The Times – January 3, 2009Bitcoin Genesis Block Mined 03 January 2009Cypherpunks Write CodeCODE IS LAW THE SOONER HUMANKIND ACCEPTS IT, THE SOONER IT CAN BUILD AROUND ITYeah.. I wonder Why 😂Bitcoin made easyHow a Bitcoin transaction worksA humble MinerHow Bitcoin Mining WorksMining DifficultyBitcoin HalvingBitcoin Previous HalvingsPoolsBitcoin WalletsBitcoin StakeholdersBitcoin FactsPower to the PeopleTotalitarian Governments can kiss my 256-bit keyBitcoin – People’s MoneyBitcoin cannot be Shut DownThe power of the long tail…Central Bank’s 3 StrategiesF**k them, Enough !!!Upcoming Smart Contracts NetworksBitcoin Yearly CandlesBitcoin Price History – Log ScaleBitcoin Mining Ecosystem MapDefi Ecosystem in EthereumDeFi Stack: Product& Application ViewSyscoin EcosystemSyscoinBSC EcosystemPopular CryptocurrencyCrpto EcosystemPublic Companies that own BitcoinTop Banks investing in CryptoBitcoin Inflation vs. TimeWhen you’re Ready…Choose WiselyMake bitcoin thrive, let fiat become humus…Veritas non Auctoritas Facit Legem
Most people misunderstand what bitcoin miners actually do, and as a result they don’t fully grasp the level of security provided by bitcoin’s hashrate.
In this article, we’ll explain proof of work in a non-technical way so that you’ll be able to counter the misinformation about supercomputers and quantum computers attacking the Bitcoin network in the future.
Simply put, mining is a lottery to create new blocks in the Bitcoin blockchain. There are two main purposes for mining:
To permanently add transactions to the blockchain without the permission of any entity.
To fairly distribute the 21 million bitcoin supply by rewarding new coins to miners who spend real world resources (i.e. electricity) to secure the network.
To understand what is actually happening in this lottery system, let’s look at a simple analogy where every Bitcoin hash is equivalent to a dice roll.
Luck, Gambling, and SHA-256
Imagine that miners in the Bitcoin Network are all individuals gambling at a casino. In this example, each of these gamblers have a 1000 sided dice. They roll their die as quickly as possible, trying to get a number less than 10. Statistically, this may take a very long time, but as more gamblers join the game, the time it takes to hit a number less than 10 gets reduced. In short, more gamblers equals quicker rounds.
Once somebody successfully rolls a number less than 10, all gamblers at the table can look down and verify the number. This lucky gambler takes the prize money and the next round begins.
Ultimately, the process of mining bitcoin is very similar. All miners on the network are using Application Specific Integrated Circuits (ASICs), which are specialized computers designed to compute hashes as quickly as possible.
To “compute a hash” simply means plugging any random input into a mathematical function and producing an output.
More hashes per second (i.e. higher hashrate) is equivalent to more dice rolls per second, and thus a greater probability of success.
Miners propose a potential Bitcoin block of transactions, and use this for an input. The block is plugged into the SHA256 hash function which yields a fixed-sized output, known as a hash. A single hash can be computed in less than a millisecond, as it involves no complex math.
If the hash value is lower than the Bitcoin Network difficulty, then the miner who proposed the block wins. If not, then the miner continues trying by computing more hashes.
The successful miner’s block is then added to the blockchain, the miner is rewarded with newly issued bitcoin for their work, and the “next round” begins.
Sources :
https://wikipedia.com/
https://braiins.com/
https://blockdata.com/
https://coin98analytics.com/
https://scoopwhoop.com/
https://stakingrewards.com/
https://syscoin.org/
https://galaxydigitalresearch.com/
https://surveycrest.com/
The Times
The Economist
"Internet of Money" - Andreas Antonopoulus
Hal Finney Quotes
Timothy C. May Quote
Free Spirit Digital Art
!°! If I forgot someone, sorry ! Do tell and I'll add you as a source of inspiration on the list !!! Thanks for understanding !!!
Questions, opinions, critics and requests always welcomed and as time allows will be accomodated !!! 🤓 🙂 😉
Did you find this article helpful?
If so, please consider a donation to help the evolution and development of more helpful articles in the future, and show your support for alternative articles.
In a first, Bitcoin developers have done something amazing amid the criticism over the lightning network and issues associated with it. A team of developers has made an international payment using the radio … Continue reading International payment using the radio waves→
My inspiration for this page was given to me by my new aquired friend, a fellow Truth Seeker – Joris and to whom I dedicate this page… Wish you… as well as to … Continue reading Discipline Quotes→
Bitcoin white paper turns 15 and the Legacy of Satoshi Nakamoto lives on. “I’ve been working on a new electronic cash system that’s fully peer-to-peer, with no trusted third party,” Satoshi Oct. 31, … Continue reading Bitcoin White Paper turn 15→
A Design For An Efficient Coordinated Financial Computing Platform
Jag Sidhu
Feb 25, 2021·41 min read
Abstract
Bitcoin was the first to attempt to offer a practical outcome in the General’s Dilemma using Crypto Economic rationale and incentives. Ethereum was the first to abstract the concept of Turing completeness within similar frameworks assumed by Bitcoin.
What Syscoin presents is a combination of both Bitcoin and Ethereum with intuitions built on top to achieve a more efficient financial computing platform which leverages coordination to achieve consensus using Crypto Economic rationale and incentives.
We propose a four-layer tech stack using Syscoin as the base (host) layer, which provides an efficient (ie, low gas cost per transaction) platform.
Some of the main advantages include building scalable decentralized applications, the introduction of a decentralized cost model around Ethereum Gas fees.
This new model proposes state-less parallelized execution and verification models while taking advantage of the security offered by the Bitcoin protocol. We may also refer to this as Web 3.0.
Table Of Contents
Abstract
Introduction
Syscoin Platform
Masternode Configuration
Chain Locks
Blockchain as a Computational Court
Scalability and Security
Efficiency
State Liveness and State Safety
Avoiding Re-execution of Transactions
Validity Proof Systems Overtop Proof-of-Work Systems
Quantum Resistance:
A Design Proposal for Web 3.0
Optimistic vs ZkRollup
Decentralized Cost Model
State-less Layer 1 Design
Related Works
Commercial Interests
Functional Overview
Give Me The Goods
Blockchain Foundry
Acknowledgements
References
Introduction
Syscoin is a cryptocurrency borrowing security and trust models of Bitcoin but with services on top which are conducive for businesses to build distributed applications through tokenization capabilities.
Syscoin has evolved since being introduced in 2013 where it offered a unique set of services through a coloured coin implementation on top of Bitcoin.
These services included aliases(identity), assets(tokens), offers(marketplace), escrow (multisig payments between aliases and marketplaces), and certificates (digital credentials).
In its current iteration, it has evolved to serve availability of consensus rather than data storage itself which requires some liveness guarantees better suited to systems like Filecoin and IPFS.
The recent iteration of Syscoin, version 4.0, streamlined the on-chain footprint to exclusively serve assets, a service which requires on-chain data availability for double-spend protection.
Ultimately, the only data that belongs on the blockchain are proofs that executions occurred (eg, coin transfers, smart contract executions, etc.) and information required to validate those proofs.
We introduced high-throughput payment rails for our asset infrastructure through an innovation we called Z-DAG [1]. This innovation offered real-time probabilistic guarantees of double-spend protection and ledger settlement for real-time point-of-sale. As a result, the token platform is one step closer to mass adoption by providing scalable infrastructure and speed that met or exceeded what was necessary to transact with digital tokens in real-life scenarios.
In addition, a two-way bridge to trustlessly interoperate with Ethereum. This enables Ethereum users to benefit from fast, cheap and secure transactions on Syscoin, and Syscoin users to leverage the Turing complete contract capabilities and ecosystem of Ethereum, all of which exclude custodians or third-parties.
Every decision we’ve made has been with security in mind. We believe that one of the biggest advantages of Syscoin is that it is merge-mined with Bitcoin.
Rather than expend more energy, Syscoin recycles the same energy spent by Bitcoin miners in order to solve blocks while being secured by the most powerful cryptocurrency mining network available.
With this energy efficiency we were able to reduce the subsidy to miners and increase subsidy to masternodes without raising the overall inflation; see Fig 1 for configuration.
Unlike Dashpay, these masternodes are not what you expect, as they have the specific job of running full nodes.
Fig 1: Masternode setup
Syscoin Platform
Today, Syscoin offers an asset protocol and deterministic validators as an enhancement on top of Bitcoin, as summarized below:
UTXO Assets
Compliance through Notary
Fungible and Non-Fungible tokens (Generic Asset infrastructure named SPT — Syscoin Platform Tokens)
Z-DAG for fast probabilistic onchain payments, working alongside payment channel systems like Lightning Networks
Deterministic validators (Masternodes) which run as Long-Living Quorums for distributed consensus decisions such as Chain Locks
Decentralized Governance, 10% of block subsidy is saved to pay out in a governance mechanism through a network wide vote via masternodes
Merged-mined with Bitcoin for shared work alongside Bitcoin miners
Masternode Configuration
With 2400+ masternodes running fullnodes, Z-DAG becomes much more dependable, as does the propagation of blocks and potential forks.
The masternodes are bonded through a loss-less strategy of putting 100000 Syscoin in an output and running full nodes in exchange for block rewards.
A seniority model incentivizes the masternodes to share long-term growth by paying them more for the longer period of service. Half of the transaction fees are also shared between the PoW miners and masternodes to ensure long term alignment once subsidy becomes negligible.
The coins are not locked at any point, and there is no slashing condition if masternodes decide to move their coins, the rewards to those masternodes simply stop.
Sharing Bitcoin’s compact block design, it consumes very little bandwidth to propagate blocks assuming the memory pool of all these nodes is roughly synchronized [2].
The traffic on the network primarily consists of propagating the missing transactions to validate these blocks. Having a baseline for a large number of full-nodes that are paid to be running allows us to create a very secure environment for users.
It proposes higher costs to would-be attackers who either have to attempt a 51% attack of Syscoin (effectively also trying to attack the Bitcoin network), or try to game the mesh network by propagating bad information which is made more difficult by incentivized full-nodes.
The health of a decentralized network consists of the following;
(a) the mining component or consensus to produce blocks, and
(b)the network topology to disseminate information in a timely manner in conditions where adversaries might be lurking.
Other attacks related to race conditions in networking or consensus code are mostly negligible as Syscoin follows a rigorous and thorough continuous development process.
This includes deterministic builds, Fuzz tests, ASAN/MSAN/TSAN, functional/unit tests, multiple clients and adequate code coverage.
Syscoin and Bitcoin protocol code bases are merged daily such that the build/signing/test processes are all identical, allowing us to leverage the massive developer base of Bitcoin.
The quality of code is reflective of taking worst case situations into account. The most critical engineers and IT specialists need confidence that value is secure should they decide to move their business to that infrastructure.
It’s true that there are numerous new ideas, new consensus protocols and mechanisms for achieving synchronization among users in a system through light/full node implementations.
However, in our experience in the blockchain industry over the last 8 years, we understand that it takes years, sometimes generations to bring those functionalities to production level quality useful for commercial applications.
Chain Locks
With a subset of nodes offering sybil resistance through the requirement of bonding 100,000 SYS to become active, plus the upcoming deterministic masternode feature in Syscoin 4.2, we have enabled Chain Locks which attempts to solve a long-standing security problem in Bitcoin [3], where Dashcore was the first project to implement this idea [4] which the industry has since widely accepted as a viable solution [5].
Our implementation is an optimized version of this, in that we do not implement Instant Send or Private Send transactions and thus Syscoin’s Chain Lock implementation is much simpler.
Because of merged-mining functionality with Bitcoin, we believe our chain coupled with Chain Locks becomes the most secure via solving Bitcoin’s most vulnerable attack vector, selfish mining.
These Chain Locks are made part of Long-Living Quorums(LLMQ) which leverage aggregatable Boneh–Lynn–Shacham(BLS) signatures that have the property of being able to combine multiple signers in a Distributed Key Generation(DKG) event to sign on decisions. In this setup, a signature can be signed on a group of parties under threshold constraints without any one of those parties holding the private key associated with that signature. In our case, the signed messages would be a ChainLock Signature (CLSIG) which represent claims on what the block hashes represent of the canonical chain [4].
This model suggests a very efficient threshold signature design was needed to be able to quickly come to consensus across the Masternode layer to decide on chain tips and lock chains preventing selfish mining attacks. See [6] to understand the qualities of BLS signatures in the context of multi-sig use cases.
Ethereum 2.0 design centers around the use of BLS signatures through adding precompile opcodes in the Ethereum Virtual Machine(EVM) for the BLS12–381 curve [7] which Syscoin has adopted.
This curve was first introduced in 2017 by Bowe [8] to the ZCash protocol. Masternodes on Syscoin use this curve and have a BLS key that is associated with each validator. There is the performance comparison to ECDSA (Secp256k1) [9] that shows its usefulness in contrast to what Bitcoin and Syscoin natively use for signature verification.
Blockchain as a Computational Court
A computational court is a way of enforcing code execution on the blockchain’s state. This was first introduced by de la Rouvier [10].
Since the inception of Syscoin and Blockchain Foundry we have subscribed to the idea that the blockchain should be used as a court system rather than a transaction processor.
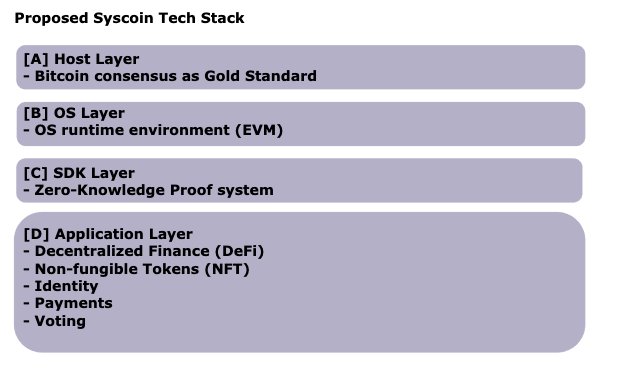
This debate has stemmed from the block size debate in the Bitcoin community [11]. However, with recent revelations in cryptography surrounding Zero-Knowledge Proofs (ZKP) [12] and particularly Zero-Knowledge Succinct Non-Interactive Argument of Knowledge(zk-STARK) [13], we propose a secure ledger strategy using the Bitcoin protocol as a court (ie, host layer), an EVM or eWASM (ie, operating system layer), computational scaling through ZKP (ie, SDK layer) and business verticals (ie, application layer); see Fig 2
Fig 2: Four-layer tech stack
Scalability and Security
Scalability in blockchain environments is typically measuredbyTotal Transactions per Second (TPS).
This means full trustlessness, decentralization and liveness properties as evidenced by something like Bitcoin.
If trade-offs are made to achieve higher scale it means another property is affected.
A full node is one that creates blocks and/or fully validates every block of transactions.
For the purpose of this discussion, we will refrain on expounding on designs where light-clients are used to give semblance of higher throughput, etc.
However, if two nodes are running the same hardware and doing the same work, the one that provides more TPS performance than the other is considered more scalable. This is not to be confused with throughput which is the measure of output that can be increased by simply adding more hardware resources. Hence, more throughput does not mean more scalable.
Some blockchains require the producers of blocks to run on higher specifications, offering higher throughput but not necessarily more scale.
However, there are projects which employ parallel processing to try to achieve higher scale whilst also enforcing more capable hardware to provide a more efficient overall system [33].
As a logical experiment, the throughput of a system divided by the scalability of the system is what we define as efficiency.
In the following sections, we will outline our proposal for improved efficiency.
Efficiency
The holy grail of blockchain design resides in the ability to have a ledger that can claim to be sublinear while retaining consistency, fault tolerance and full availability (ie, CAP Theorem).
This means there are roughly constant costs for an arbitrary amount of computation performed and being secured by that ledger.
This has always been thought of as impossible and it mostly is unless acceptable trade-offs appear in application designs and they are easy to understand and work around.
Most experts make the assumption that an O(1) ledger is simply impossible and thus design blockchains and force applications to work in certain ways as a result.
We will remove such assumptions and let business processes dictate how they work by giving the ability to achieve O(logk n) for some constant k (ie, polylogarithmic) efficiency with trade-offs.
A polylogarithmic design would give the ability for almost infinite scaling over time for all intents and purposes.
The only bottlenecks would be how fast information can be propagated across the network which would improve over time as telecom infrastructure naturally evolves and increases in both capability and affordability.
Put in context, even Lightning Networks for transactional counts qualifies as a form of sublinear scaling on a transactional basis but not per user, as users must necessarily enter the main chain first before entering a payment channel.
It requires the state of the blockchain to include the users joining the system.
This state (the UTXO balances) is the single biggest factor of efficiency degradation in Bitcoin.
Users need to first start on the main chain and then move into the payment channel system to receive money, meaning that scale is at best O (N) where N is the number of users.
There are some solutions to this problem of state storage on Bitcoin by reducing it via an alternative accumulator strategy to the cost of increased bandwidth [14].
This approach would make the chain state-less, however the validation costs would remain linear to the number of transactions being done. When combined with payment channels, only the costs to get in/out are factored into the validation and this offers an interesting design for payments themselves while providing for on-chain availability.
We consider this as a good path for futuristic scalable payments.
Hence, it is not possible to employ that strategy with general computations. With this design, we are still left with the issue on how to do general computations at higher efficiency.
What we present is the ability to have a polylogarithmic chain at the cost of availability for both payments and general computations where business processes dictate availability policies, and users fully understand these limitations when using such systems.
Users may also be provided the ability to ensure availability for themselves and others at their discretion. This will be expounded upon in the following sections.
State Liveness and State Safety
While many compelling arguments can be made migrating to a state-less design [15], it is not possible to achieve sublinear efficiency without sacrificing some other desired component that we outlined above.
To achieve polylogarithmic efficiency it’s necessary to have a mix of state and stateless nodes working together in harmony on a shared ledger [15].
This should be accomplished in such a way that business processes can dictate direction, and users can choose to pay a little more for security either by using a stateful yet very scalable ledgering mechanism or by paying to ensure their own data availability amortized over the life of that user on such systems.
Presenting the ability for users to make these choices allows us to separate the consensus of such systems and reduce overall complexity.
However, in whatever solution we adopt , we need to ensure that the final implementation allow for both the liveness and safety of that state, which are defined as follows:
State Liveness — Transferring coins in a timely manner
State Safety — Private custody
It is important to adhere to these concepts; if one cannot move one’s coins, then it is as useful as if one burned their coins. Hence, if we had third party custody in place, this would give rise to custodial solutions, and lose decentralized and trustless aspects of the solution, which again is not desired.
The options as described would allow users to decide their state liveliness at their own discretion, while state safety is a required constraint throughout any system design we provide. The doorway to possibilities of sublinear design is opened by giving users the ability to decide.
Avoiding Re-execution of Transactions
In order to scale arbitrarily, independent of the number of transactions — a desired property of increasing throughput — one requires a mechanism to avoid re-executing transactions.
Further, ideally it would be able to batch these transactions together for a two-fold scaling proposition.
There are a few mechanisms in literature that attempted to solve re-execution:
Unfortunately, they require challenge response systems to ensure security, which leads to intricate attack vectors of unbounded risk/reward scenarios.
Multi-Party Computation (MPC) is a mechanism to have parties act under a threshold to decide on actions such as computational integrity of a smart contract. MPC is used in Syscoin for BLS threshold signatures for Chain Locks and Proof-of-Service in quorums of validators deterministically chosen using Fiat-Shamir heuristics on recent block hashes.
The problem with this approach is that validators may become corrupt, hence need to be wrapped in a consensus system along with DKG and random deterministic selection. This was an interesting topic of discovery for the Syscoin team early-on as a way to potentially scale smart contract execution but was ultimately discarded due to the incentive for risk/reward scenarios to favour attacks as the value of the transactions increases.
Hardware enclaves (eg, Intel SGX through remote attestation) were also of particular interest to the Syscoin team as a way to offload execution and avoid re-execution costs.
However, there are a myriad of attack vectors and censorship concerns on the Intel platform . We also should note that the Antarctica model was interesting but required a firmware update from Intel to support such a feature which raises concerns over censorship long term.
The theme amongst all of these approaches is that although re-execution is avoided the communication complexity is largely still linear with the number of transactions on the main chain. The security and trust models are also different from that of the layer 1 assumptions which was not desired. Lacking solvent solutions to avoid re-execution and enable sublinear overall complexity, we were led — in the development of Syscoin 4.0 — to build a trust-minimized two-way bridge between Syscoin and the Ethereum mainchain, offloading the concerns around smart contracts to Ethereum.
With the advent of such promising technology as ZKP and the optimizations happening around them, we have re-considered the possibilities and believe this will play an important role in the development of Web 3.0. This mathematical breakthrough led us to re-test our assumptions and options related to our desired design.
ZKP allows us the desired superlinear scaling trait we had been looking to achieve but they also offer other benefits; namely privacy is very easy to introduce and will not add detectable costs and complexities to verification on the mainchain.
With users controlling their own data, the mainchain and systems may be designed such that only balance adjustments are recorded, not transaction sets (we will explain the case with full data availability below). In this scenario there is no advantage for a miner to gain to be able to collude with users to launch attacks on systems such as Decentralize Finance (DeFi) pools and provenance of transactions.
The flexibility has to be there though for application developers that need experiences consistent with those we have today with Bitcoin/Syscoin/Ethereum, and to enable the privacy use-cases without requiring extra work, knowledge or costs.
Fig 3: Host and EVM layer
Validity Proof Systems Overtop Proof-of-Work Systems
Prior to the use of Proof Systems, the only option for “Validity Proofs” in a permissionless system involved naive replay, and as such greatly limited scalability; in essence this replay is what is still done today in Layer-1 blockchain (L1) solutions, with the known penalty to scalability.
Proof Systems offer a very appealing trait known as succinctness: in order to validate a state transition, one needs to only verify a proof, and this is done at a cost that is effectively independent of the size of the state transition (ie, polylogarithmic in the size of the state transition).
For maximal financial security, the amount of value being stored should depend on the amount of security provided on the settlement side of the ledger.
Proof-of-Work offers the highest amount of security guarantees. Our next generation financial systems begin with optimal ledgering security and add proof systems on top for scaling. Block times are not as important in a world where most users and activity are on Layer-2 blockchain (L2) validity proof based systems.
This liberates engineers who are focused on scalability to define blocks better; safe block times plus the maximal amount of data bandwidth that can be safely propagated in a time sensitive manner across full nodes in the network.
In Syscoin there are incentivized full nodes (ie, deterministic masternodes), so again we can maximize the bandwidth of ledgering capabilities while retaining Bitcoin Proof-of-Work (PoW) security through merged-mining.
Quantum Resistance:
Table 1: Estimates of quantum resilience for current cryptosystems (see [20])
As seen in Table 1, hashing with the SHA256 algorithm is regarded to be quantum safe because it requires Grover’s algorithm to crack in the post-quantum world, and at best the quantum computer will offer only 50% reduction in time to break.
On the other hand, where Shor’s algorithm applies, any pair based cryptographic system will be broken in hours.
For L2, we propose to implement ZKP in the SDK Layer (see Fig 2); namely Non-Interactive Zero Knowledge Proofs(NIZKP).
Popular implementations of NIZKP include Zero-Knowledge Succinct Non-interactive ARgument of Knowledge(zk-SNARKS) and Zero-Knowledge Scalable Transparent ARguments of Knowledge(zk-STARKS).
There are some zk-STARK/zk-SNARK friendly cipher’s employed in zkRollup designs such as MiMC and Pederson hashes for which we lack certainty on classical security, yet are hopeful and would offer quantum resistance within ZKPs.
It is important to note that Bitcoin was developed with change addresses in mind exposing the hash of a public key requires a quantum computer to use Grover’s Algorithm in order to attempt stealing that Bitcoin. Each time a Bitcoin Unspent Transaction Output(UTXO) is spent, the public key is exposed and a new change address — which does not expose the public key — is used as change.
With this in mind, any scalable L2 solution should be quantum resistant because otherwise we undermine Bitcoin design as the gold standard of security.
Fig 4: zkSync Rollup design
A Design Proposal for Web 3.0
The following describes the 4-layers (see Fig 2) of Syscoin’s proposed tech stack for Web 3.0:
[Host Layer] Bitcoin’s design is the gold standard for security and decentralization.
Proof-of-work and Nakamoto Consensus settlement security are widely regarded by academics as the most hardened solution for ledgering value.
It’s possible this may change, however it’s also arguable that the intricate design encompassing Game Theory, Economics, risk reward ratios for attack, and the minimal amounts of compromising attack vectors is likely not to change for the foreseeable future.
UTXO’s (and payments with them) are more efficient than account-based or EVM-based. That said, Bitcoin itself suffers from not being expressive enough to build abstraction for general computation.
[Operating System Layer]
EVM/eWASM is the gold standard for general computation because of its wide adoption in the community.
Anyone building smart contracts are likely using this model or will continue to use it as the standard for autonomous general computation with consensus.
[SDK Layer]
Zero-knowledge proofs are the gold standard for generalized computation scaling for blockchain applications. They enable one-time execution via a prover and enable aggregate proof checking instead of re-execution of complex transactions.
zk-STARKs or zk-SNARKs using collision resistant hash functions that work with only weak cryptographic assumptions and therefore are quantum safe.
At the moment generalized smart contracts are not there yet but we are quickly approaching the day (eg, Cairo, Zinc) when there will be abstractions made to have most Solidity code trans-compile into a native zero-knowledge aware compiler similar to how .NET runtime and C# allows an abstraction on top of C/C++ as an interpretive layer on top
[Application Layer]
Verticals or applications applying the above SDK to define business goals.
Surprisingly, these ideals represent a design that is not shared with any other project in the industry, including Bitcoin or Ethereum.
We feel these ideals, fashioned together in a singular protocol, could possibly present a grand vision for a “World Computer” blockchain infrastructure.
Syscoin has already implemented Geth + Syscoin nodes in one application instance already (ie, release 4.2), we foresee that it will not prove too challenging to have them cooperate on a consensus basis working together to form a dual chain secured by Syscoin’s PoW.
Fig 5: Proposed design
Fig 5 describes a system where nodes are running two sets of software processes, the Syscoin chain protocol and an EVM/eWASM chain protocol which are kept in sync through putting the EVM tip hash into the Syscoin block. Both have their own individual mempools and effectively the Ethereum contracts, tools and processes can directly integrate as is into the EVM chain as it stands.
Note that the two chains are processes running on the same computer together. Thus a SYS NODE and EVM NODE would be operating together on one machine instance (ie, Masternode) with ability to communicate with each other directly through Interprocess Communication(IPC).
The intersection between the two processes happens in three points:
Miner of the EVM chain collects the latest block hash and places it into the Syscoin block.
When validating Syscoin blocks, nodes confirm the validity of the EVM tip by consulting the EVM chain software locally.
Fees for the EVM chain are to be paid in SYS. We need an asset representing SYS on the EVM chain, which will be SYSX.
We will enable this through a similar working concept that we’ve already established (SysEthereum Bridge).
We may also enable pre-compiles on the EVM chain side to extract Syscoin block hashes and merkle roots to confirm validity of SYS to SYSX burn transactions.
This design separates concerns by not complicating the PoW chain with EVM execution information, keeping the processes separate yet operating within the same node.
To further delineate point 1 (see above), a miner would mine both chains. With Syscoin being merged-mined, the work spent on Bitcoin would be shared to create a Syscoin block that includes the EVM chain within it as a ledgering event representing the latest smart contract execution state (composed of Chain Hash, State Root, Receipt Root, and Transaction Trie Root).
Since the EVM chain has no consensus attached, technically a block can be created at any point in time. Creation of Syscoin and EVM blocks will be near simultaneous, and occur every one minute on average.
Fig 6: Merge mining on Syscoin
As seen in Fig 6, work done on BTC is reused to create SYS blocks through the merged-mining specification. Concurrently, the miner will execute smart contracts in the memory pool of the node running the EVM chain. Once a chain hash has been established post-execution, it will be put into the coinbase of the Syscoin block and published to the network. Upon receiving these blocks, every node would verify that the EVM chain which they would locally execute (ie, similar to the miner) matches the state described by the Syscoin block.
Technically, one would want to ensure both the latest and previous EVM block hashes inside of their respective Syscoin blocks are valid.
The block->evmblock == evmblock && block->prev == evmblock->prev is all that is needed to link the chains together with work done by Bitcoin which is propagated to Syscoin through AUXPOW and can serve as a secure ledgering mechanism for the EVM chain.
There has been much discussion as to what the safe block size should be on Ethereum. Gas limits are increasing as optimizations are made on the Ethereum network.
However, since this network would be ledgered by the Syscoin chain through PoW, there would be no concern for uncle orphaning of blocks since the blocks must adhere to the policy set inside of the Syscoin block. We should therefore be able to increase bandwidth significantly and parameterize for a system that will scale globally yet still be centered around L2 rollup designs.
A very important distinction here is that the design of Ethereum 2.0 centers around a Beacon chain and sharding served by a Casper consensus algorithm. The needs of the algorithm require a set of finality guarantees necessitating a move towards Proof-of-Stake (PoS).1
This has large security implications for which we may not have formal analysis for a long time, however we do know it comes with big risk.
We offer similar levels of scalability on a network while retaining Nakamoto Consensus security. The simpler design which has been market tested and academically verified to work would lead to a more efficient system as a whole with less unknown and undocumented attack vectors.
The only research that would need to be made therefore is on the optimal parameterization of the gas limit taking into account an L2 centric system but also a safe number of users we expect to be able to serve before fee market mechanisms begin to regulate the barrier of entry for these users.
This proposed system should be scalable enough to serve the needs of global generalized computation while sticking to the core fundamentals set forth in the design ideals above. Our upcoming whitepaper will have more analysis on these numbers but we include some theoretical scaling metrics at the end of this article.
Optimistic vs ZkRollup
ZKP are excellent for complex calculations above and beyond simple balance transfers. For payments, we feel UTXO payment channels combined with something like Z-DAG is an optimal solution.
However, we are left with rollup solutions for generalized computation involving more complex calculations requiring consensus.
Whatever solution we adopt has to be secured by L1 consensus that is considered decentralized and secure, which we achieve via merged-mining with Bitcoin.
There are two types of rollup solutions today:
(a) Optimistic roll ups (OR); and (b) zkRollups; which offer trade-offs.
Consensus about which chain or network you’re on is a really hard problem that is solved for us by Nakamoto consensus. We build on that secure longest chain rule (supplemented by Chain Locks to prevent selfish mining) to give us the world-view of the rollup states. The executions themselves can be done once by a market of provers, never to be re-executed, only verified, meaning it becomes an almost constant cost on an arbitrarily large number of executions batched together. With OR you have the same world-view but the world-view is editable without verifying executions. The role of determining the validity of that world-view is delegated to someone watching who provides guarantees through crypto-economics. Zero-knowledge proofs remove crypto-economics on execution guarantees and replace them with cryptography.
See [26] to see contrasting benefits between fraud proofs (optimistic) vs validity proofs (zk)
Key takeaways from this article are as follows
Eliminate a nasty tail risk: theft of funds from OR via intricate yet viable attack vectors;
Reduce withdrawal times from 1–2 weeks to a few minutes;
Enable fast tx confirmations and exits in practically unlimited volumes;
Introduce privacy by default.
One point missing is interoperability. A generalized form of cross-chain bridging can be seen in Chain A locking tokens based on a preimage commitment by Chain B to create a zero-knowledge proof, followed by verification of that proof as the basis for manifesting equivalence on Chain B. Any blockchain with the functionality to verify these proofs could participate in the ecosystem.
Our vision here is described using a zkRollup centric world-view, yet it can be replaced with other technologies should they be able to serve the same purpose. As an infrastructure we are not enforcing one or the other; developers can build on what they feel best suits their needs. We believe we are close to achieving this, and that the technology is nearing the point of being ready for the vision set forth in this article.
Decentralized Cost Model
Decentralized cost models lead to exponential efficiency gains in economies of scale. We set forth a more efficient design paradigm for execution models reflective of user intent. This design uses the UTXO model to reflect simple state transitions and a ZKP system for complex computations leading to state transitions. This leads to better scalability for a system by allowing people to actively make their trade-off within the same ecosystem, driven by the same miners securing that ecosystem backed by Bitcoin itself.
Furthermore, a decentralized cost model contributes to scalability in that ZKP gates can generalize complex computation better than fee-market resources like gas or the CPU/memory markets of EOS, etc.
This leads to better scalability for a system by allowing people to actively make their trade-off within the same ecosystem, driven by the same miners securing that ecosystem backed by Bitcoin itself.
Furthermore, a decentralized cost model contributes to scalability in that ZKP gates can generalize complex computation better than fee-market resources like gas or the CPU/memory markets of EOS, etc. This leads to more deterministic and efficient consumption of resources maximizing efficiency in calculations, and gives opportunity for those to scale up or down based on economic incentives without creating monopolistic opportunities unlike ASIC mining.
In other words, the cost is dictated by what the market can offer, via the cost of compute power (as dictated by Moore’s law), rather than the constrained costs of doing business on the blockchain itself.
This model could let the computing market dictate the price for Gas instead of being managed by miners of the blockchain. The miners would essentially only dictate the costs of the verification of these proofs when they enter the chain rather than the executions themselves.
We can already begin to see computational optimization through hardware happening with ZKP and with a decentralized cost model it will be much easier to understand costs of running prover services as well as know how the costs scale based on the number of users and parameters of systems that businesses would like to employ. All things considered, it will be easier to make accurate decisions on data availability policies and the consensus systems needed to keep the system censorship resistant and secure.
Rollups will be friends, that is, users of one rollup system doing X TPS and users of another doing Y TPS, with the same trust model, will in effect get us to global rates of X*Y (where X is TPS of the sidechains/rollups and Y is the number of sidechains and rollups that exist). X is fairly static in that the execution models of rollups do not change drastically (and if they do, the majority of those rollup or sidechain designs end up switching to the most efficient design for execution over time).
State-less Layer 1 Design
The single biggest limiting factor of throughput in blockchains is state growth and access to the global state.
More specifically, in Bitcoin it is the UTXO set, and in Ethereum it is the Account Storage and World State tries. State lookups typically require SSD in Ethereum full nodes because real-time processing of transactions of block arrivals are critical to reaching consensus, this is especially the case for newly arriving blocks (ie, every 10–15 seconds).
As state and storage costs rise, the number of full verifying nodes decreases due to the resource consumption of fully validating nodes and providing timely responses to peers. Consequently, network health suffers due to the risks of centralization of consensus amongst the subset peers running full nodes.
State-less designs are an obvious preference to solve problems using alternative mechanisms to validate the chain without requiring continuous updates to the global state.
In a rollup, smart contracts on L1 do not access the global state unless entering or exiting a rollup. Therefore smart contracts that provide full data availability on-chain (ie, zkRollup), would only require state updates to the local set of users within that L2. Under designs where data availability is kept off-chain, there is no state update on L1, unless entering and exiting.
Therefore, it classifies as purely state-less, whereas in zkRollup mode we can consider this partially state-less. Since these L1 contracts are state-less to the global state, nodes on the network can parallelize verification of any executions to the contracts which do not involve entering or exiting. This is in addition to the organic and natural parallel executions of transactions that are composing these rollup aggregated transactions posted on L1.
State-less layer 1 designs also allow for parallelizable smart contract execution verification. The parallelization of smart contracts running on L1 in the EVM model is a recent topic of research that some projects have implemented in production which involves defining “intent” for the execution of a contract (because nodes do not know ahead of time what the smart contract execution will entail in terms of accessing global state).
Adding in the intent of a transaction as supplied as part of the commitment of that transaction would allow nodes to reject if the execution of that contract did not correspond with the intent, possibly costing the user fees for invalid commitments.
Although these designs may be flexible, they come at the cost of additional complexity through sorting, filtering and general logic that may be susceptible to intricate attacks.
In our case, the transaction can include a field that is understood by the EVM to denote if it is intending to use global state in any way (for rollups typically this would be false) then we can simply reject any access to global states for those specific types of executions.
This would allow nodes to execute these specific types of transactions in parallel knowing that no global state is allowed to access executions. If a transaction is rejected due to incorrectly setting this field the fees are still spent to prevent users from purposefully setting this field incorrectly.
Related Works
The following organizations offer various open source third party L2 scaling solutions:
Starkware is built using a general purpose language (Cairo) with Solidity (EVM) in mind, as is Matter labs with the (Zinc) language. Hermez developed custom circuits tailor-suited to fast transactions and Decentralized Exchange (DEX) like capability. These will be able to directly integrate into Syscoin without modification.
As such, the optimizations and improvements they make should directly be portable to Syscoin, hence becoming partners to our ecosystem.
Aleo uses Zero knowledge EXEcution(Zexe) for zkSNARK proof creation through circuits created from R1CS constraints. The interesting thing about Aleo is that there is a ledger itself that is purpose-built to only verify these Zexe proofs for privacy preserving transactability. The consensus is PoW, while the proof system involves optimizing over the ability to calculate the verifications of these proofs efficiently.
The more efficient these miners become at verifying these proofs, the faster they are able to mine and thus the system provides sybil resistance through providing resources to verify Zexe proofs as a service in exchange for block creation.
However, these proof creations can be done in parallel based on the business logic for the systems the developers need to create. There is no direct need for on-chain custom verification as these can be done in an EVM contract, similar to what Cairo Generic Proving Service (GPS) verifier and Zinc Verification do.
The goal of Aleo is to incentivize miners to create specialized hardware to more efficiently mine blocks with verification proofs.
However, provers can also do this as we have seen with Matter Labs’ recent release of FPGA to do more efficient zkSNARK proofs [27]. It is a desirable property to use PoW to achieve “world-view” consensus in Aleo; however they focus on private transactions. They are typically not batched and employ a recursive outer proof to guarantee execution of an inner proof where the outer proof is sent to the blockchain to be verified. This proof is a limited 2-step recursion, consequently batching of arbitrary amounts of transactions is not supported.
However, as a result the cost of proof verification is relatively constant with a trade-off of limiting the recursion depth. Aleo is not meant to be a scalable aggregator of transactions, but mainly oriented towards privacy in their zk-SNARK constructions using Zexe.
Commercial Interests
Commercial enterprises may start to create proprietary prover technologies where costs will be lower than market in an attempt to create an advantage for user adoption. This design is made possible since the code for the prover is not required for the verifier to ensure that executions are correct. The proof is succinct whether or not the code to make the proof is available.
While the barrier of entry is low in this industry, we’ve seen the open source model and its communities optimize hardware and software and undergo academic peer review using strategies that outpace private funded corporations.
That is plausible to play out over the long term. However, an organic market will likely form on its own, forging its own path leading to mass adoption through capitalist forces.
The point here is that the privately funded vs open source nature of proving services does not change the mechanism of secure and scalable executions of calculations that are eventually rooted to decentralized and open ledgers secured by Bitcoin.
The utmost interesting propositions are the verticals that become possible by allowing infrastructure that is parameterized to scale into those economies where they are needed most, and where trust, security and auditability of value are concerns.
Smart cities, IoT, AI and Digital sovereignty are large markets that intersect with blockchain as a security blanket.
Although ZKP are tremendously useful on their own, applying them to consensus systems for smart contract executions drive them to another level due to the autonomous nature of “code-is-law” and provable deterministic state of logic. We believe a large majority of the next generation economy will depend on many of the ideas presented here.
Blockchain Foundry is working with commercial and enterprise adopters of blockchain technology. Our direct interaction with clients combined with our many collective years of experience in this field are reflected in this design.
Functional Overview
Fig 7: High-level description
For scalable simple payments, one can leverage our Syscoin Platform Token (SPT) asset infrastructure and payment channels to transact at scale.
Unique characteristics of SPTs include a generalized 8 byte field for the asset ID which is split between the upper and lower 4 bytes; the upper 4 are issued and definable (ie, NFT use cases) and lower 4 are deterministic. This enables the ability to have a generalized asset model supporting both Non-fungible Tokens (NFT) and Fungible Tokens (FT) without much extra cost at the consensus layers. 1 extra byte is used for all tokens at best case and 5 extra bytes are used for NFT at worst case.
This model promotes multiple assets to be used as input and consequently as outputs, suggesting that atomic swaps between different assets are possible within 1 transaction. This has some desirable implications when using payment channels for use cases such as paying in one currency when merchants receive another atomically.
A multi-asset payment channel is a component that is desired so users are not constrained to single tokens within a network. Composability of assets as well as composability across systems (such as users from one L2 to another) is a core fundamental to UX and convenience that needs to be built into our next generation blockchain components that we believe will enable mass adoption.
The Connext box shows how potentially you can move from one L2 on one network to another as described in [29]. This would promote seamless cross-chain L2 communication without the high gas fees. Since these L2’s are operating under an EVM/eWASM model, there are many ways to enable this cross-communication.
An EVM layer will support general smart contracts compatible with existing Ethereum infrastructure and L2 rollups will enable massive scale. The different types of zkRollups will allow businesses and rollup providers to offer ability for custom fee markets (ie, pay for fees in tokens other than base layer token SYS).
In addition, it will remove costs and thus improve scale of systems by offering custom data availability consensus modules. This design discussed here shares similarities to the zkPorter design where a smart contract would sign off on data availability checks that would get put into the ZKP as part of the validity of a zkBlock which goes on chain.
The overall idea of the zkPorter design is that the zkRollup system would be called a “shard”, and each shard would have a type either operating in “zkRollup” mode or operating in “normal” mode.
Taken from the zkPorter article the essence of it is:
If a shard type is zkRollup, then any transaction that modifies an account in this shard must contain the changes in the state that must be published as L1 calldata (same as a zkRollup).
Any transaction that modifies accounts in at least two different shards must be executed in zkRollup mode.
All other transactions that operate exclusively on the accounts of a specific shard can be executed in normal shard mode (we will call them shard transactions). If a block contains some shard transactions for a shard S, then the following rules must be observed:
The root hash of the subtree of the shard S must be published once, as calldata on L1. This guarantees that users of all other shards will be able to reconstruct their part of the state.
The smart contract of the data availability policy of this shard must be invoked to enforce additional requirements (e.g. verify the signature of the majority of the shard consensus participants).
This concludes that shards can define different consensus modules for data availability (censorship resistance mechanisms) via separating concerns around ledgering the world-view of the state (ie, ZKP that is put on L1 and the data that represents the state. Doing so would allow shards to increase scale, offload costs of data availability to consensus participants.
A few note-worthy examples of consensus for data availability are:
Non-committee, non fraud proof based consensus for data availability checks. No ⅔ online assumption; see ethresear.ch post [30].
Sublinear block validation of ZKP system. Use something like Lazy Ledger as a data availability proof engine and majority consensus; see ethresear.ch post [31].
Use a combination of above, as well as masternode quorum signatures for any of the available quorums to sign a message committing to data availability checks as well as data validity. Using masternodes can provide a deterministic set of nodes to validate decisions as a service. The data can be stored elsewhere accessible to the quorums as they reach consensus that it is indeed valid and available.
Give Me The Goods
You may be wondering what a system like this can offer in terms of scale …
Simple payments: since payment channels work with UTXO’s and also benefit from on-chain scaling via Z-DAG, 16MB blocks (with segwit weight) assumed, we will see somewhere around 8MB-12MB effectively per minute (per block).
We foresee that is sufficient to serve 7 Billion people who may enter and exit the payment channel networks once a year (ie, 2 transactions on chain per person per year) for a total of 14 Billion transactions.
Let’s conservatively assume 8MB blocks and 300 bytes per transaction. Once on a payment channel, the number of transactions is not limited to on-chain bandwidth, but to network related latencies and bandwidth costs. Therefore, we will conclude that our payment scalability will be able to serve billions of people doing 2 on-chain transactions per year which is arguably realistic based on the way we envision payments to unfold; whether that is an L2 or payment channel network that will hold users to pay through instant transaction mechanisms.
On-chain, we have some metrics on Z-DAG throughput [1]; in those cases someone needs to transact for point-of-sale using the Syscoin chain. The solution for payments ends up looking like a hybrid mechanism of on-chain (Z-DAG) and off-chain (ie, payment channel) style payments.
Complex transactions such as smart contracts using zkRollups require a small amount of time to verify each proof. In this case, we assume that we will host data off-chain while using an off-chain consensus mechanism to ensure data availability for censorship resistance; so the only thing that goes on the chain are validity proofs. We will assume that we will assign 16MB blocks for the EVM chain per minute.
A proof size will be about 300kB for about 300k transactions batched together which will take about 60–80ms to verify and roughly 5 to 10 minutes to create such proofs.
These are the Reddit bake-off estimates using zk-STARKs which present quantum resistance and no trusted setup.
After speaking with Eli Ben-Sasson, we were made aware that proving and verifications metrics are already developed compared to what is currently presented by Starkware [34].
Hence, zk-SNARKs offer even smaller proofs and verification times at the expense of trusted setups and stronger cryptography assumptions (not post-quantum safe).
We foresee that these numbers will improve over time as the cryptography improves, but current estimates suggest a rough theoretical capacity of around 1 Million TPS.
Starkware was able to process 300k transactions over 8 blocks with a total cost of 94.5M gas; final throughput was 3000 TPS (see Reddit bake-off estimates). As a result, or the following calculations, let’s assume one batch-run to be 300k transactions.
Ethereum can process ~200kB of data per minute, with a cost limit of 50M gas per minute. Therefore, considering the Starkware benchmark test, and assuming a block interval of 13 seconds, we would achieve ~ 3000 TPS (ie, 300 k transactions per batch-run / (8 blocks per batch-run * 13 seconds per block))
It is estimated that Syscoin will be able to process ~16MB of data per minute on the EVM layer (ie, SYSX in Fig 3), which is ~80x gain over Ethereum; thus a cost limit of 4B gas (ie, 80*50M) per minute.
Therefore, if the Starkware benchmark test was run on Syscoin, it is estimated that Syscoin could run the equivalent of 42 batch-runs per minute (ie, 4B gas per minute / 94.5 M gas per batch-run).
That would result in an equivalent of 210 k TPS (ie, 42 batch-runs per minute * 300 k transactions per batch-run / 60 seconds per minute).
If we were to consider using Validum on the Syscoin EVM layer, we estimate that we could achieve 800 batch-runs per minute (ie, 4B gas per minute / 5 M gas per batch-run). That would equate to an equivalent of 4M TPS (ie, 800 batch-runs per minute * 300 k transactions per batch-run / 60 seconds per minute).
Table 2: Gas costs and Total throughput
* Because all transactions are on-chain, which would include state lookups and modifications, it would likely result in a smaller total throughput depending on the node. This would be on average somewhere between 50–150 TPS total due to the state lookup bottlenecks, which are not an issue in a rollup design and can be done in a state-less way on-chain (meaning the throughput can instead be bounded by computational verification of the ZKPs)
**Rollups post the transitions on-chain and Validium does not, but note that the transitions on chain are account transitions and not transactions and so if some accounts interact within the same batch it will be just those account transitions recorded to the chain regardless of how many actual transactions are done between them.This is the minimum TPS with full layer 1 decentralized security. The amortized cost per Tx thus drops as accounts are reused within the This is the minimum TPS with full layer 1 decentralized security. The amortized cost per Tx thus drops as accounts are reused within the batch and the total TPS would subsequently rise.
Optimizations to the verification process are likely and would be required to get to those numbers, but the bandwidth would allow for such scale should those optimizations come to fruition.
For example 800 zk-STARK verifications at roughly 80ms per zk-STARK would take around 64 seconds, however these proofs can be verified in parallel so with a 32-core machine. It would take ~2–3 seconds total spent on these proofs, and likely decrease further with optimizations (note that TPS includes total account adjustments).
The aforementioned calculations demonstrate the full State Safety of the mainchain secured by Bitcoin, and no asynchronous network assumptions which make theoretical calculations impractical in many other claims of blockchain throughput due to execution model bottlenecks.
These results were extrapolated based on real results with constant overhead added that becomes negligible with optimizations. It is imperative to note that transactions in this strategy are not re-executable; there is little to no complexity in this model other than verifying succinct proofs. The proof creation strategy is parallelized organically using this model. The verifications on the main chain can also be parallelized as they are executed on separate shards or rollup networks. Dual parallel execution and verification gives exponentially more scalability than other architectures.
Additionally, privacy can be built into these models at minimal to no extra cost, depending on the business model. Lastly, we suggest these are sustainable throughput calculations and not burst capacity numbers which would be much higher (albeit with a marginally higher fee based on fee markets).
For example Ethereum is operating at 15 TPS but there are around 150k transactions pending, and the average cost is about 200 gWei currently. The fee rate is based on the calculation that it takes around 10000 seconds to clear, assuming this many transactions, no new transactions, and there is demand to settle earlier.
Extrapolating on 4M TPS the ratio would become 40B transactions pending with 4M TPS to achieve the same fee rate on Ethereum today assuming the memory pool is big enough on nodes to support that many pending transactions.
Since masternodes on Syscoin are paid to provide uptime, we can expect network bandwidth to scale up naturally to support higher throughput as demand for transaction settlement increases.
Today, the ability to transact at a much higher rate using the same hardware provides the ability for a greater scale than the state-of-the-art in blockchain design without the added desired caveat of avoiding asynchronous network assumptions.
We believe this proposed design will become the new state-of-the-art blockchain, which is made viable due to its security, flexibility and parallelizable computational capacity.
In regards to uncle rates with higher block sizes, keep in mind we make uncle rates and re-organizations in general negligible through the use of the PoW chain mining Syscoin along with Chain Locks. We provide intuition that block sizes can be increased substantially without affecting network health.
Furthermore, the gas limits can be adjusted by miners up to 0.1% from the previous block and so a natural equilibrium can form where even if more than 4B gas is required it can be established based on demand and how well the network behaves with such increases.
There is a lot to unpack with such statements and so we will cover this in a separate technical post as it is out-of-scope for this discussion.
Blockchain Foundry
One of the main reasons for a profit company is to take advantage of some of the aforementioned verticals which we expect to underpin the economies of tomorrow with infrastructure similar to what is presented here.
Since the company’s beginning in 2016, we have spent the majority of our existence designing architecture parameterized to global financial markets.
Breakthroughs in cryptography and consensus designs as described here lead us to formalize these designs to apply to market verticals, formulating new applications and solutions that would not have been possible before.
Specifically, , we believe these ideas can be IP protected without requiring privatization of the entire tech stack. These value-added ideas that will use existing open-source tech stacks enabling a massive network effect of value through incentivization of commercial and enterprise adoption.
These new ideas, innovations and proprietary production quality solutions could steer in a new wave of prosperity for civilization.
References
[1] J. Sidhu, E, Scott, and A. Gabriel, Z-DAG: An interactive DAG protocol for real-time crypto payments with Nakamoto consensus security parameters, Blockchain Foundry Inc, Feb. 2018. Accessed on: Feb 2021. [Online]. Available: https://syscoin.org
[3] I. Eyal and E. G. Sirer, Majority is not enough: Bitcoin mining is vulnerable, Proceedings of International Conference on Financial Cryptography and Data Security, pp. 436–454, 2014.
[11] Anonymous Kid, Why the fuck did Satoshi implement the 1 MB blocksize limit? [Online forum comment], Jan 2018, Accessed on: Feb 2021. [Online]. Available: https://bitcointalk.org/index.php?topic=2786690.0
[12] Zero-Knowledge Proofs What are they, how do they work, and are they fast yet? Accessed on: Feb 2021. [Online]. Available: https://zkp.science/
[13] E. Ben-Sasson, I. Bentov, Y. Horesh, and M. Riabzev, Scalable, transparent, and post-quantum secure computational integrity, IACR Cryptol, 2018, pp 46
[14] Dryja, T, Utreexo: A dynamic hash-based accumulator optimized for the bitcoin UTXO set, IACR Cryptol. ePrint Arch., 2019, p. 611.
[16] S. Bowe, A. Chiesa, M. Green, I. Miers, P. Mishra, H. Wu: Zexe: Enabling decentralized private computation. Cryptology ePrint Archive, Report 2018/962 (2018). Accessed on: Feb 2021. [Online]. Available: https://par.nsf.gov/servlets/purl/10175111
[17] A. Nilsson, P.N. Bideh, J. Brorsson, A survey of published attacks on Intel SGX. 2020, arXiv:2006.13598
[20] Quantum Computing’s Implications for Cryptography (Chapter 4), National Academies of Sciences, Engineering, and Medicine: Quantum Computing: Progress and Prospects. The National Academies Press, Washington, DC, 2018.
[24] V. Buterin and V. Griffith, Casper the Friendly Finality Gadget. CoRR, Vol. abs/1710.09437, 2017. arxiv: 1710.09437, http://arxiv.org/abs/1710.09437
[25] M. Neuder, D.J. Moroz, R. Rao, and D.C. Parkes, Low-cost attacks on Ethereum 2.0 by sub-1/3 stakeholders, 2021. arXiv:2102.02247, https://arxiv.org/abs/2102.02247
[32] T. Chen, X. Li, Y. Wang, J. Chen, Z Li, X. Luo, M. H. Au, and X. Zhang. An adaptive gas cost mechanism for Ethereum to defend against under-priced DoS attacks. Proceedings of Information Security Practice and Experience — 13th International Conference ISPEC, 2017
[33] Y. Sompolinsky, and A. Zohar, Secure High-rate Transaction Processing in Bitcoin, Proc. 19th Int. Conf. Financial Cryptogr, Data Secur. (FC’20), Jan 2015, pp. 507–527
[34] Starkware Team, Rescue STARK Documentation — Version 1.0, Jul 2020